Claude and ChatGPT are getting worse. It's not your imagination.
AI models are quietly hitting their limits and the companies are rationing capacity without telling you. Here's what's actually happening, why it affects the tools you use every day, and what you can do about it.

If you've noticed that ChatGPT feels slower lately, or that Claude cuts off mid-task, or that a response that used to take seconds now takes much longer, you're not imagining it.
What's happening isn't a bug. It's a structural problem that the AI industry has been reluctant to discuss openly: the infrastructure that powers these models is running out of capacity, and the companies building them are quietly making trade-offs that directly affect the quality of what you get.
First, you need to understand what tokens are
When you send a message to an AI, the model doesn't read your words the way you wrote them. It reads fragments of words called tokens.
👉 A simple question might cost between 500 and 1,000 tokens. A one-hour working session with an AI agent (the kind where it's drafting, revising, searching, and executing tasks) can consume between 50,000 and 500,000 tokens!
That last number is the one that matters. Agentic AI (AI that takes sequences of actions rather than answering a single question) uses between 10 and 100 times more compute than a simple prompt. As more people use AI for more complex tasks, the total demand on the infrastructure has exploded. And the infrastructure hasn't kept up.
The signs are visible across every major platform.
Claude, currently one of the most widely used AI models, had an API uptime of 98.95% during parts of this year. That sounds close to fine until you do the math: the industry standard is 99.99%, which equals about four minutes of downtime per month. At 98.95%, that's nearly 24 accumulated hours of outages.
March 2026 was the worst single month: Claude was down for 13 hours.
In response, Anthropic imposed token limits during peak hours — specifically between 5 and 11am Pacific time. For users in Europe, that translated to limits kicking in between 1pm and 7pm: the middle of the working day. To soften the blow, they ran a "spring break" campaign doubling token limits outside those peak windows — the same strategy electric companies use with off-peak pricing.
Anthropic's latest model, Claude Opus 4.7, consumes 46% more tokens than its predecessor for the same amount of text. The price didn't change. What changed is that your quota runs out significantly faster than it used to. And in late April, Anthropic quietly updated its pricing page to move coding capabilities — previously included in standard paid plans — to plans costing $100 or $200 per month. Users caught it on social media, Anthropic reversed the decision, but the intent was clear.
OpenAI shut down Sora — its video generation app — on March 24, 2026, just six months after launch. The app had reached one million downloads in its first week. It was also burning one million dollars per day in compute costs, with minimal revenue to offset it.
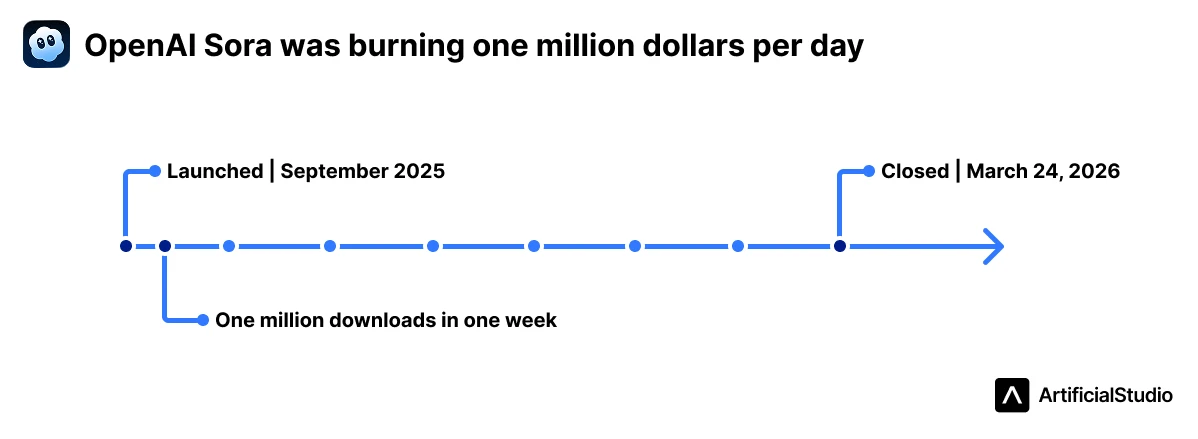
OpenAI had a signed deal with Disney worth over a billion dollars for access to Marvel, Star Wars, and Pixar IP. That deal is now on hold.
Google's Gemini has seen four silent cuts in four months between December 2025 and March 2026. In December, the free tier dropped 92% in daily request capacity overnight, with no prior notice. By March, even users on the most expensive subscription tier had their limits reduced without any communication.
Why the companies aren't fixing it faster
The AI industry is aware of the problem and is spending aggressively to address it.
Major tech companies are collectively investing over $700 billion this year in expanding and building new data centers 💸. The goal is to triple current electrical capacity for AI infrastructure.
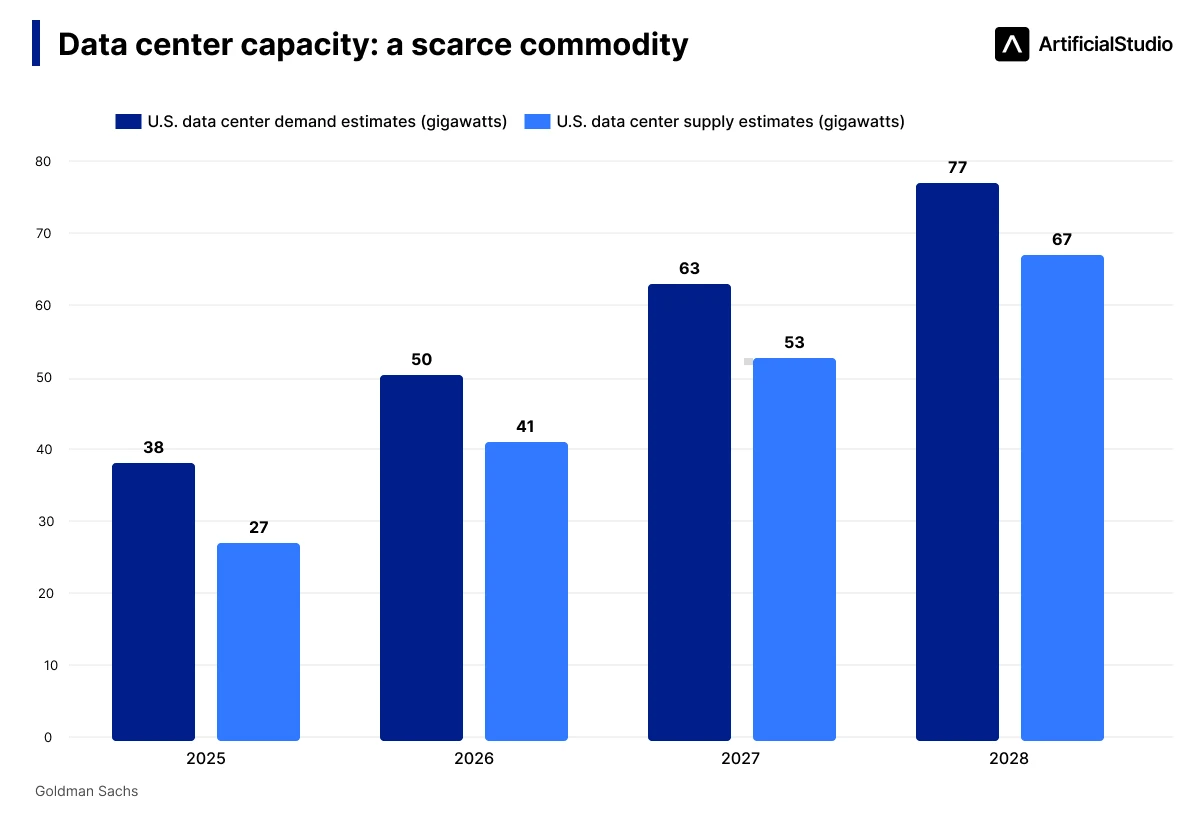
But Goldman Sachs projects that demand will continue to outpace supply by 10 gigawatts of electricity per year through at least 2028. The money exists. The bottlenecks — materials sourced from abroad, permits, and a shortage of qualified engineers in the US — are slowing everything down. Stargate, the $500 billion infrastructure project announced in January 2025, had its planned Texas facility paused as of April 2026.
The comparison that puts this in perspective: mobile phones took roughly 15 years to reach mass adoption. Agentic AI went from niche to ubiquitous in about 18 months. The infrastructure crisis is the same in nature. The timeline to fix it is much tighter.
There's also a financial dimension that shapes every decision these companies make. OpenAI is projected to lose $14 billion in 2026.
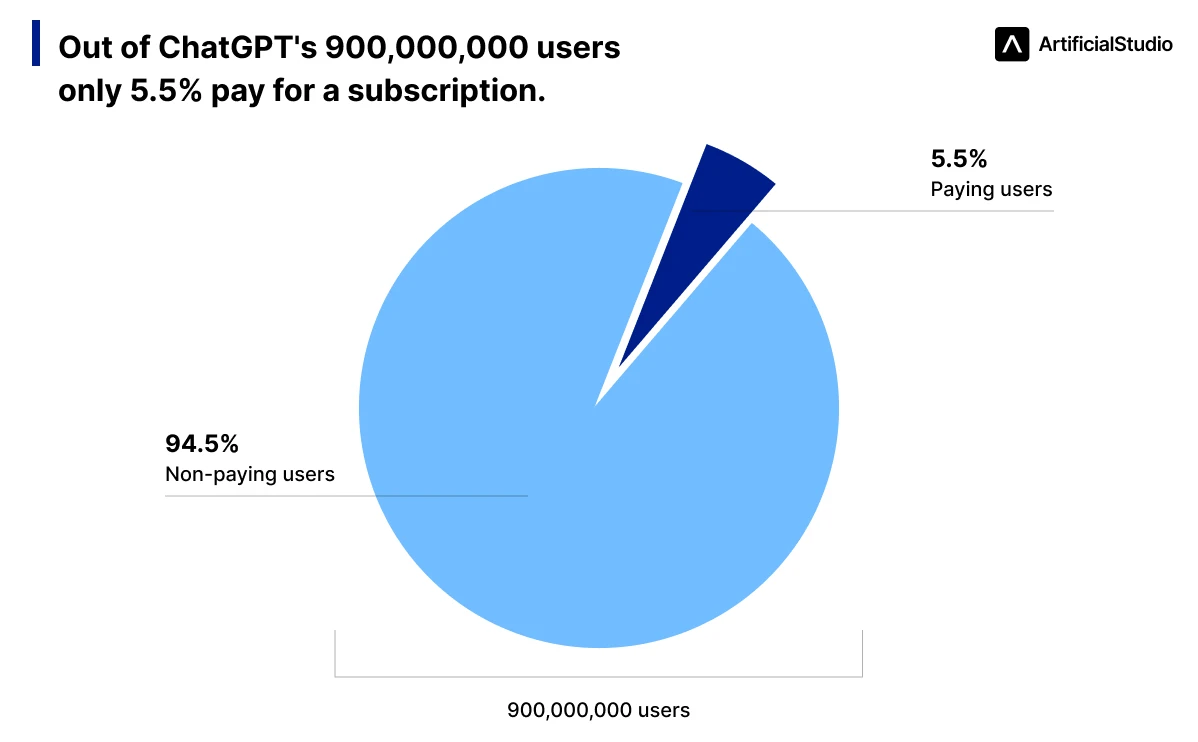
Anthropic lost an estimated $3 billion in 2025. Only 5.5% of ChatGPT's 900 million users currently pay for the service — meaning OpenAI is effectively subsidizing the compute costs of the remaining 94.5% out of its own capital. That is not a sustainable model, and everyone in the industry knows it.
OpenAI has confirmed that during periods of high demand, free users receive slower responses from less capable models with fewer advanced features.
If compute is scarce and expensive, the companies that can pay more will get more of it.
Better AI means better decisions, better output, better competitive position — which means they can pay even more. It's a self-reinforcing loop.
What this means if you use AI for creative work
Quality fluctuates in ways that are completely invisible to the end user. You don't get a notification saying "today's responses are running at 70% capacity." You just get a shorter answer, a task that cuts off, or a result that's noticeably less precise than what you got last week.
For creative professionals, people using AI to generate images, edit video, produce audio, write copy, develop concepts, this inconsistency has real production consequences. A tool that performs unpredictably is a tool you can't build a workflow around.
Stop depending on a single model for everything.
When one model is under capacity strain, another might not be. Testing the same brief across different models (and knowing which one is performing well on a given day) is increasingly a professional skill, not a luxury.
Platforms like Artificial Studio are built for exactly this: you can run the same prompt across different models and compare results in seconds. If one model is underperforming, you switch. The quality of your output doesn't have to depend on whether one company's servers are having a bad week.
This is a transitional moment, not a permanent state. The infrastructure will eventually catch up, it always does. But the period between now and then will be defined by limits, quiet degradations, and pricing models that reward whoever pays most with the best experience.
Understanding the mechanics behind it means you're not caught off guard when your tool hits a wall: what tokens cost, why capacity gets rationed, how these companies are structured financially. You know what's happening, and you know how to work around it.


